We've been crawled!

This is the weakest flex ever, but our website has been crawled, and its public content scrapped by Google to train its large language mode AI. It also means we've been on the map for all ChatGPT versions and other competing models, trying to catch up on OpenAI. Why is it such a weak flex? Because we're not Wikipedia, and even with more than a thousand articles published, we're only 0.00003% of the content crawled:
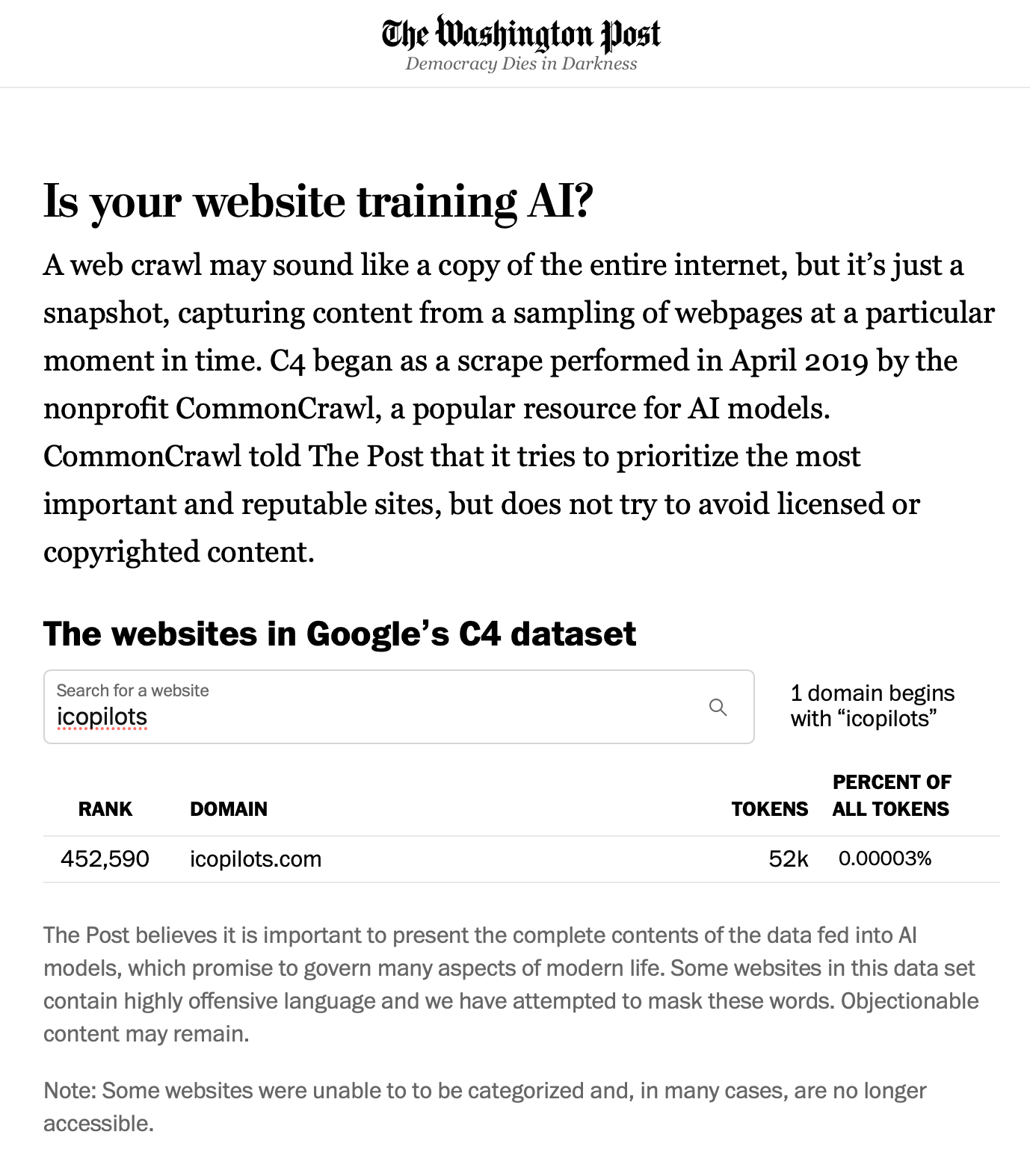
The top domains that are currently used to train these large language models are certainly interesting as to which they are and how much they're weighting in these AI training also gives you an idea of the bias they will have as an output:
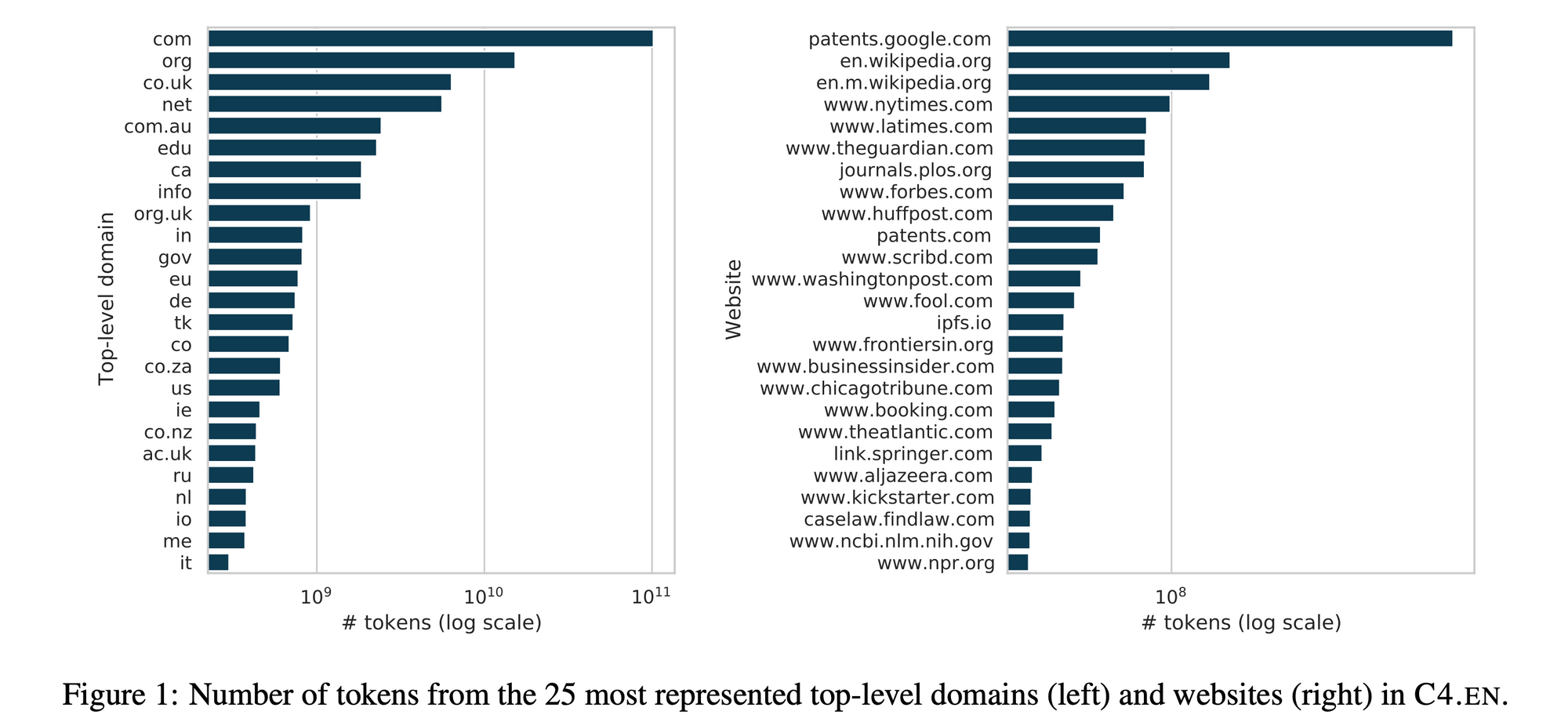
Interesting point: websites like Reddit that have been massively crawled are starting to ask for financial compensation. What deal will be brokered and how these sites will be able to control what's going on, in any case, remains quite unclear at this point. Not to mention that most AI developers don't care about mentioning which sites they crawled and if the content was copyrighted or not...
I wonder if we'll get $12 as a class-action compensation twelve years from now? I'm certainly glad that our weekly newsletter is beyond an email subscription until ChatGPT5 is unleashed, and we'll be able to subscribe by itself 😱

