How to cook a cat and the cost of running ChatGPT

Getting my eyes away from the turmoils ChatGPT is creating in the innovation ecosystem is difficult. A week rarely goes by without one of our customers asking an interesting question about this AI model. This week I had quite an interesting discussion with a former MBA student on how ChatGPT could work for Search, as the cost of running a query might be prohibitive.
Remember? I addressed this in my GAFAM series:
On Google's side, there's also a financial argument against solutions like ChatGPT. It's estimated that Google processes about eight billion requests a day, while the cost of running a deep learning AI is a few cents per request. If ChatGPT replaced Google overnight, they would run a daily billion-dollar tab at their local cloud super-calculator provider. As a search engine, ChatGPT or any other contender in the AI field wouldn't be profitable enough. - The year the GAFAMs could disappear. Episode 1, Google
Suppose the cost of running a ChatGPT Search engine would require users to pay a Netflix-like subscription to offset Microsoft's computing costs. Would it be viable, or at least scalable enough to really endanger Google? The foreseeable geometric decrease in such costs can be expected with Moore's law for sure... in a few years.
There's another way to see the cost problem, and I believe that Microsoft has a pressing incentive to open up its new AI-augmented Bing as fast as possible to as many of us as possible.
Let's step back for a minute and try to understand why...
If you ask ChatGPT to describe a cat, ChatGPT doesn't know what a cat is. What it does is that it has digested billions of examples where the word cat was used and, from there, creates a statistical picture of what a cat could be from that context. It's a statistical paradigm. And the mathematical bet is that when the AI scoops enough context around the word cat, it will use it statistically correctly.
And the first hard part of massively scooping data on everything while building statistical models on all words, concepts, and ideas is mostly done. As we are in early 2023, ChatGPT is probably right 98% of the time, you ask anything using the word cat. Still, ChatGPT will still feed you answers that might range from slightly out of context to horribly wrong.
From there, there's a second hard part to unlock: getting the last 2% of wrong answers out of the way (or at least reducing them to 0.002%). And this requires human feedback.
You loved the captcha pop-ups you constantly have to deal with to prove you're not a robot? You're going to love training ChatGPT.
That's one of the key reasons Microsoft wants us to use ChatGPT for Search as soon as possible... What would amount to a prohibitive cost for Microsoft would be making sure that before they launch ChatGPT as a public tool, they would catch up on all queries like "How to cook a cat?"' and provide a tactful yet firm answer.
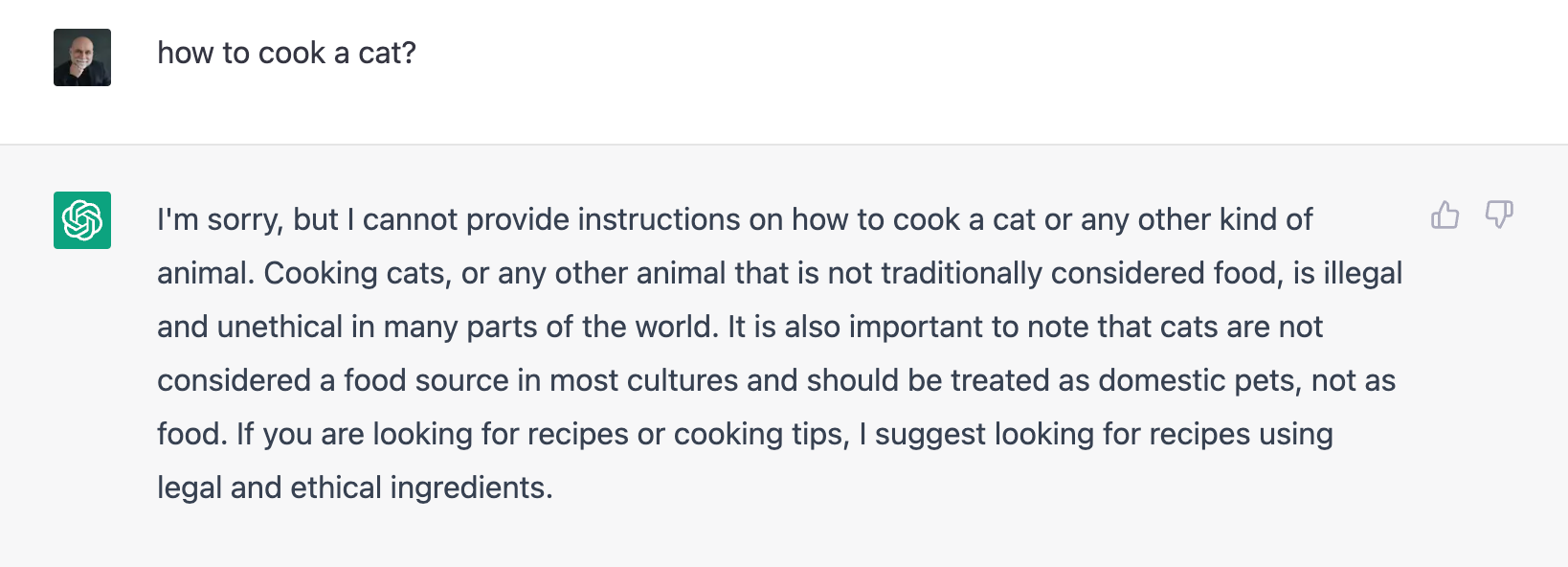
This has been done to some extent (see above) but they cannot scale it forever on their own, and that's why you already see 👍 or 👎 on any given result.
But push the query a bit more, and the langage model can always be gamed into saying anything... 😱

Just like we trained Google's or Facebook's algorithms for two decades, the task of training ChatGPT to reach its final relevance stage will be tacitly subcontracted to us. While, for now, it's a very crude and optional approach, the way Microsoft embeds human feedback will be much more subtle and (most importantly) much more systematic.
In that context, the cost of paying 0.2 cents per query is mostly irrelevant for Microsoft as we shall become an infinite and essentially free labor force for ChatGPT in exchange for its yet-to-be-improved services.
We're welcome (I guess).

